
Redis多服务下主从复制
前言
Redis是一个key-value内存存储系统,由C语言编写并提供了多种语言API操作实现。数据存储在内存中会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,也就是说Redis在数据存储层面可通过文件的形式进行。从应用层面看,Redis目前多用作缓存服务。常用于Tomcat集群下Session共享,数据库数据缓存以及分布式锁操作。由此可见,Redis多处于高并发、高负荷情况下使用。那单服务必然存在性能瓶颈,服务集群化在大规模高并发下尤为突出。按个人理解,目前常用Redis集群有两类。
1、Sentinel 哨兵高可用
2、Cluster集群
其实不管用那种方式,都离不开Redis的主从关系,个人觉得两者的区别在于Cluster会吧不同的Key数据存在不同的Redis服务上,而Sentinel则是每个都复制一遍(通过这一点可以按实际环境选择使用哪种方式)。所以本文只关注主从之间的关系,具体集群部署可自行查阅相关资料;
使用复制的原因
通过前言可以知道,Redis内部存储的数据是可以通过文件的方式体现的,这就为我们提供了数据复制的前提。那为什么需要做复制呢?
当我们进行主从分离之后,对外部请求来说相当于是多个不同的Redis服务了,那这时候如果我们写入值到Redis里,再读的时候就会出现写入与读取的数据不一致的情况,所以需要通过一种机制来同步两个服务的数据。要实现大数据同步并且最大程度不影响现有服务的运行,最理想的方式就是通过文件异步同步(异步就可能导致同步过程中产生 了新数据,这里Redis也是由应对方案的,下文会说明)
复制的原理
主从复制到底是怎么复制的呢?又是什么情况下才会触发复制操作?
主从复制目前确认两个版本(由书《Redis设计与实现》了解到),2.8以前是通过旧版本复制,2.8以后通过新版本复制。但不管新旧原理都差不多,只是新版本更优化了复制效率,避免了不必要的数据复制过程,具体原理如下:
主从主要实现读写分离(主写,从读)
旧版本:
Redis复制操作主要分两个部分:同步(sync)和命令传递(command propagate):
1、同步就是把主服务器的数据库状态更新到从服务器上,实现状态全量同步。
同步操作一般只在初次复制和断线重连时触发,当从服务器接收到SLAVEOF命令时会与主服务器执行同步操作,将从服务器的数据库状态更新为与主服务器状态一致,然后再发送sync命令给主服务器进行同步:
主服务器收到sync命令后会执行BGSAVE命令,在后台生成一个RDB的文件,并且使用一个缓冲区记录从此刻开始执行的所有写命令。
当主服务器的BGSAVE命令执行完毕时,主服务器会将生成RDB文件发送给从服务器,从服务器接收并载入这个RDB文件,将自己的数据库状态更新到与主服务器执行BGSAVE命令时一致
由于这个过程是耗时操作,期间主服务器也会产生写操作,所以最后需要将BGSAVE命令之后主服务器的写操作命令也发送到从服务器,从服务器执行这些写命令,使得自己的状态完全与主服务器同步。
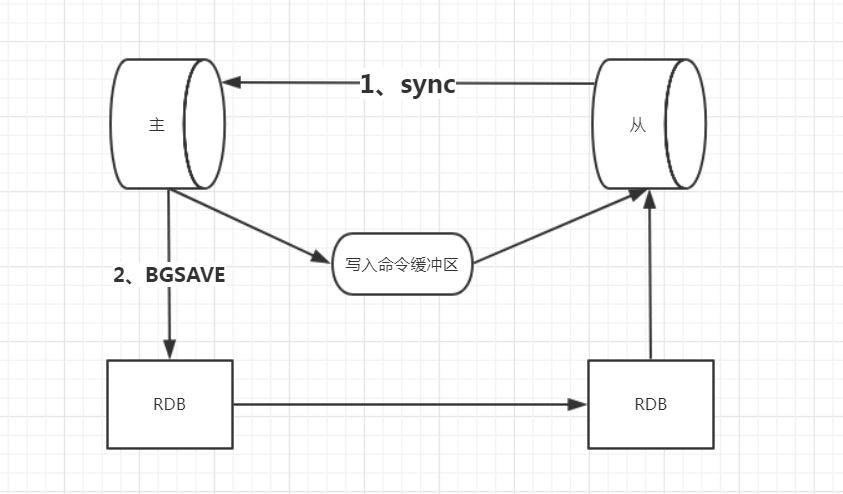
2、命令传递则是当主服务器状态与从服务器状态不一致时让主从服务器状态同步
执行完同步操作后,主从服务器之间的数据库状态已经一致,但之后如果主服务器执行了写操作还会出现状态不一致的情况。所以需要通过命令传递操作,把同步之后主服务器产生的写操作同步到从服务器上。
结论:
通过上面的操作可以发现,同步命令是一个十分耗时的操作,当出现断线重连的时候需要执行全量的同步操作。但是,有时是没必要的,如果断线重连耗时比较短,此时主从数据库的差异不大,执行同步操作是非常不可取的。每次执行BGSAVE命令都会耗费大量的CPU和内存来生成RDB文件,RDB文件传输过程也会损耗大量的网络资源。从服务器还需要载入RDB文件,并且期间从服务器会阻塞而无法处理命令请求。
新版本:
为了解决旧版本中SYNC执行时机的问题,新版本提出了一个新的命令PSYNC,并使用PSYNC命令替代了老的SYNC同步操作。而PSYNC大致可以分为 完整重同步 和 部分重同步两中操作。
1、完整重同步用于初始化复制的情况,与SYNC命令操作步骤基本一样
2、部分重同步则用于处理断线重连后的复制操作,如果满足条件,则主服务可以将从服务器在断线期间的写命令发送给从服务器进行状态更新同步。
那么部分重同步还会有一个疑问,就是当我们断线时间比较长,使得需要传递的写命令非常多的时候,效率反而会不如全同步的快。这里PSYNC的操作就提出了一个新的概念 复制偏移量。
复制偏移量分主服务器和从服务器两部分,主从服务器都会记录一个运行ID,同时主服务器会存在一个复制积压缓冲区。主服务器每次向从服务器发送N字节数据时都会将自己的复制偏移量加N,从服务器每次接收到数据后也会把偏移量加N,通过比较两边的偏移量可以判断是否一致的状态。
复制偏移量在断线重连后的作用
假如从服务器断线后立即重新连接上了主服务器,那从服务器就会向主服务器发送PSYNC命令并告诉主服务器当前从服务器的复制偏移量是多少,这是主服务器会按照一点的标准判断(这个标准由复制积压缓冲区决定)是通过部分重同步还是完整重同步操作。
那假如这个时候需要进行部分重同步操作,主服务器应该怎么把断线期间的写命令发给从服务器呢?
复制积压缓冲区
复制积压缓冲区是由主服务器维护的一个固定长度的FIFO队列。当主服务器进行写命令传播时,除了要向从服务器发送写命令外还会将写命令入队到积压缓冲队列里。所以在主服务器的复制积压缓冲队列里会保留最近一段时间内传递给从服务器的写命令,而复制积压缓冲区会为队列中的每一个子杰都记录上相应的偏移量,当从服务器断线重连后PSYNC发送给主服务器的偏移量就是根据这个队列里的偏移量来找到需要传递给从服务器的写命令。同样的,如果偏移量不存在与队列,则需要执行完整重同步命令了。
服务器运行ID
部分重同步除了需要通过复制积压缓冲区外,还需要使用到服务器的运行ID。每一个Redis的服务都会有自己的运行ID,启动时生成,由40位随机的十六进制字符组成。当服务器初次复制时,主服务器会将自己的ID传递给从服务器。从服务器会将这个ID报错起来,当从服务器断线重连后会向当前连接的主服务器发送报错的ID,如果ID相同则前后连接的主服务器一致,执行部分重同步操作。如果不同则要执行完整全同步操作。

0 Responses to "Redis多服务下主从复制"